Your classifier's default threshold is a bug
An AUC of 0.90 told me the model was good. A 0.5 cutoff told the business it was useless. Here's how I closed that gap on a production RCM classifier.

The model scored an AUC of 0.90. I was pleased with myself for about a day, until someone in operations asked why it was flagging so many claims that clearly didn’t need review. The model was good. The way I was using it was not.
The culprit was the threshold — the cutoff that turns a predicted probability into a yes/no decision. Almost every library defaults to 0.5, and almost no real problem wants 0.5.
Why 0.5 is rarely right
A 0.5 threshold assumes two things that are almost never true in production: that your classes are balanced, and that a false positive costs the same as a false negative. In revenue cycle management neither holds. The positive class (claims needing a specific action) is a minority, and the cost of chasing a claim that didn’t need it is not the same as the cost of missing one that did.
AUC hides this entirely. It measures ranking quality across all thresholds, so a model can rank beautifully and still make terrible decisions at the one threshold you actually ship.
Optimizing for the decision, not the ROC
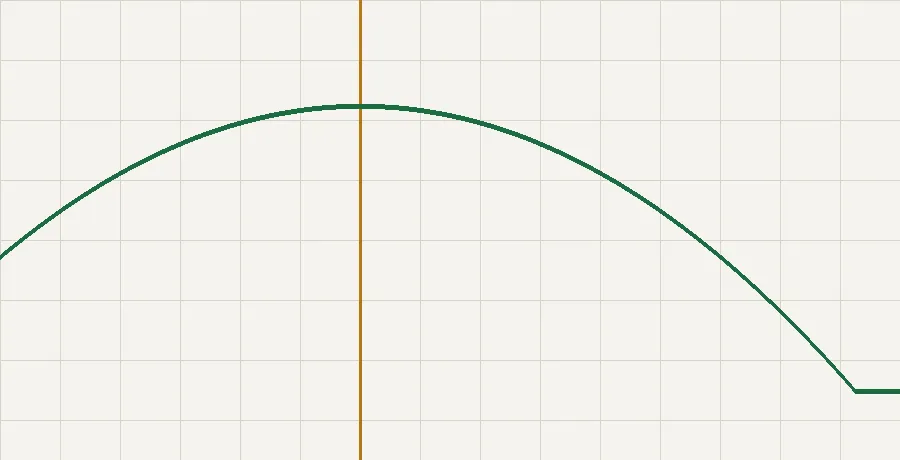
The fix is to pick the threshold against the metric the business actually feels. For this pipeline that was F1 on the positive class. I swept thresholds across the validation set and looked at where F1 peaked:
import numpy as np
from sklearn.metrics import f1_score
probs = model.predict_proba(X_val)[:, 1]
thresholds = np.linspace(0.05, 0.95, 181)
scores = [(t, f1_score(y_val, probs >= t)) for t in thresholds]
best_t, best_f1 = max(scores, key=lambda s: s[1])
print(f"best threshold = {best_t:.3f} | F1 = {best_f1:.3f}")The peak sat well below 0.5. Moving the cutoff there lifted F1 from roughly 0.58 at the default to about 0.67 — without retraining a single tree.
Two things I’d warn you about
Tune on validation, evaluate on test. The threshold is a learned parameter. If you pick it on your test set you’ve leaked, and your reported number is optimistic.
Re-check the threshold when the data drifts. The optimal cutoff is a property of the score distribution, and that distribution moves as the population moves. I fold a threshold re-fit into the same job that does model versioning, so a new model never ships with a stale cutoff.
The model was never the problem. The decision rule was. Worth remembering that
the last line of predict is as much a part of the system as the first.